 Byte brevi: Il web crawler è un programma che naviga in Internet (World Wide Web) in modo predeterminato, configurabile e automatizzato ed esegue determinate azioni sui contenuti sottoposti a ricerca per indicizzazione. I motori di ricerca come Google e Yahoo utilizzano lo spidering come mezzo per fornire dati aggiornati.
Byte brevi: Il web crawler è un programma che naviga in Internet (World Wide Web) in modo predeterminato, configurabile e automatizzato ed esegue determinate azioni sui contenuti sottoposti a ricerca per indicizzazione. I motori di ricerca come Google e Yahoo utilizzano lo spidering come mezzo per fornire dati aggiornati.
Webhose.io, una società che fornisce accesso diretto ai dati in tempo reale da centinaia di migliaia di forum, notizie e blog, il 12 agosto 2015, ha pubblicato gli articoli che descrivono un minuscolo crawler web multi-thread scritto in Python. Questo crawler Web Python è in grado di eseguire la scansione dell'intero Web per te. Ran Geva, l'autore di questo minuscolo web crawler in Python, afferma che:
Ho scritto come "Dirty", "Iffy", "Bad", "Not very good". Dico, porta a termine il lavoro e scarica migliaia di pagine da più pagine in poche ore. Non è richiesta alcuna configurazione, nessuna importazione esterna, basta eseguire il seguente codice Python con un sito seed e sedersi (o fare qualcos'altro perché potrebbe richiedere alcune ore o giorni a seconda della quantità di dati necessari).Il crawler multi-thread basato su Python è piuttosto semplice e molto veloce. È in grado di rilevare ed eliminare i collegamenti duplicati e di salvare sia l'origine che il collegamento che possono essere utilizzati in seguito per trovare collegamenti in entrata e in uscita per il calcolo del page rank. È completamente gratuito e il codice è elencato di seguito:
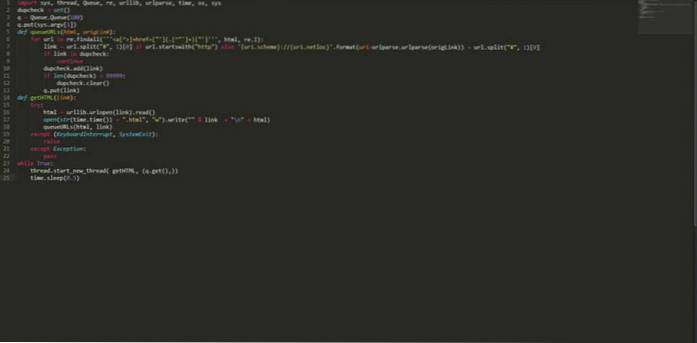
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): per l'URL in re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] if url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] if link in dupcheck : continue dupcheck.add (link) if len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): try: html = urllib.urlopen (link) .read () open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) tranne (KeyboardInterrupt, SystemExit): raise eccetto Eccezione: pass mentre True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Salvare il codice sopra con un nome diciamo "myPythonCrawler.py". Per iniziare a eseguire la scansione di qualsiasi sito Web, digita:
$ python myPythonCrawler.py https://fossbytes.com
Siediti e goditi questo web crawler in Python. Scaricherà l'intero sito per te.
Diventa un professionista in Python con questi corsi
Ti piace questo semplice crawler web multi-thread basato su Python? Fatecelo sapere nei commenti.
Leggi anche: Come creare USB avviabile senza alcun software in Windows 10